挖掘历史数据 捕捉未来信息 把握运营趋势
客户世界|万平 李成 段娜|2012-11-06
客服中心行业的很多管理者已经清晰意识到预测在平稳运营保障和KPI管理过程中具有举足轻重的地位,也有很多人——尤其是客服中心运营管理系统开发团队或专门的WFM(劳动力管理)系统厂商对于创新预测工作做了很多的尝试和开发,包括从数据选取、指标选取、方法选取到预测工具选取……但从前期交流的情况来看,这些工作的开展最终都会不约而同地聚焦于模型建立和工具实现,而对于预测的定义、预测的流程以及预测的关注要素等,探讨并不深入,这也导致了很多产品在上线测试预测效果时总不能尽如人意,尴尬的是普遍受到了客户较强烈的不解、担心甚至质疑。
本文作者根据多年来进行金融行业客服中心运营数据分析和预测的经验,试图从运营排班预测的角度与大家交流对预测工作的定义理解,重点介绍预测流程的实践,同时简要介绍所使用的预测模型理论,希望能抛砖引玉。
一、预测定义思考
预测:数据信息之综合分析。客服中心囊括了人力资源、运营管理、客户信息、外部因素、业务知识、技术系统等诸多方面的丰富数据信息,这些数据信息综合体现了客服中心运营的整体状况和过程细节,要做好预测工作就必须对客服中心的发展历程和发展现状深入熟悉,因此要做好预测也就要综合分析好各个层面的数据。
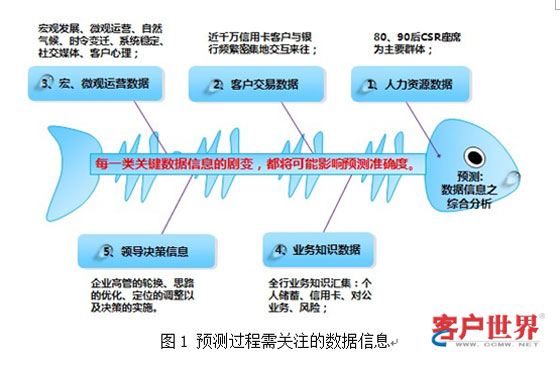
二、预测流程实践
预测流程:“挖掘历史数据,捕捉未来信息,把握运营趋势。”这句话是作者在多年数据分析和预测工作中历经无数次成功与失败之后总结得出的,在做预测时应该严格遵照这个流程,力求保持“众人皆醉我独醒”的工作状态。
1、挖掘历史数据:预测的思想是将与时间推移紧密相关的数据看成一个随机序列,从序列历史值和当前值的规律中合理外推未来的值,并用一定的数学模型来近似描述这种序列,因此建立合理的预测模型也就成为挖掘历史数据的核心任务,这也是诸多产品在预测工作上的聚焦点,其重点工作就是对历史数据进行因素分析、模式识别、参数估计、假设检验、未来预测。
对于序列预测模型,目前业界常用的方法有简单平均法、加权平均法、移动平均法、逐级分解法,另外高等计量经济学对于时间序列的预测有回归模型、ARIMA模型、灰色预测、神经网络、组合模型预测等。不管是哪种预测模型,其核心思想均是通过刻画历史数据的长期趋势因子、周期变动性因子、季节变动性因子和不规则扰动性因子来演绎未来趋势(如图1)。这些模型的差异也就表现在对这些因子刻画能力的强弱,其中高等计量经济学的相关模型能更为出色地地描述了序列的长期趋势因子、周期变动性因子、季节变动性因子。
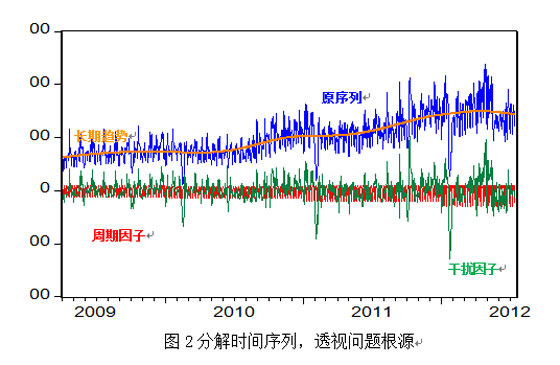
注:因为具体数据涉及到企业机密,故对数据进行了相应处理
而对于不规则趋势,因为其更多地受到随机因素或偶然因素影响,不能单纯从历史数据中得到很好的刻画,在建模型时往往用一个扰动项综合描述,恰恰也是这个扰动项成为各种预测模型的“软肋”之所在。从统计建模的角度来看,这种“软肋”在模型中又是不可避免的:如果要使模型能精确地拟合历史数据则会导致“过拟合”的现象,使模型未来趋势的整体预测能力下降;如果增加模型扰动项中所含的信息,则会使模型对某些特殊日期预测效果下降。要解决这一矛盾、减少“软肋”的风险,需要重视以业务背景和影响因素驱动的数据分析和客户行为挖掘。
在我们的预测工作中有十二大类、41个子类的特殊或随机因素需要经常关注和分析,十二大类包括短信影响、客户量增长、交易量增长、运营政策调整、还款日、节休日、业务或系统优化、系统未预期性故障、关键特殊日重叠、宏观经济政策、同业关联影响、自然环境影响、时令冷暖变迁。这些因素是致使上图(图2)序列大起大落的主要原因。
以短信影响为例来说明业务数据分析对于保证预测准确性的重要作用。一般情况下,符合如下情形之一的短信都会致使客户密集来电:额度调整、风险提示、费用收取、信息核实、账户变动、高概率中奖、目标客户群精准、利益提示。银行与客户的沟通过程中会有许多短信:提示类短信、通知类短信、营销类短信、关怀类短信。不同短信发出去后,客户的反应程度是完全不同的。账单短信属于涉及客户切身利益的费用收取或利益提示短信,其对运营影响较大。通过大量数据分析和对比得知,账单短信发送出去后有如下稳定规律:(1)30分钟左右进入密集回呼阶段;(2)60~90分钟内进入回呼高峰期;(3)、发送后4个小时左右影响基本消退。其属于逐步消退型,客户回呼行为较为稳定。根据这些数据特征,在预测时就能清晰地考虑其影响大小和时段:首先对于日预测只需要把握住短信发送量就可准确的测算出其影响大小;其次对于时段预测,可以根据短信发送的时间和数量准确推算出其回呼的高峰时段和回呼量(如图3)。

另外,综合考虑实际排班规划与呼入量之间的拟合情况,我们对账单短信的发送时间和频次进行了调整,将原来的“时段均匀发送”调整为“时段歧视发送”,这样能较好地满足三种情况:(I)短信回呼高峰能适当错开,将原来的尖峰调整为波浪式;(2)人力较富余的下午时段安排密集发送;(3)因为其需要4小时才逐步消退,又不影响17:00左右的下班高峰点运营。
预测模型和历史数据分析相辅相成,有机地构成了挖掘历史数据这一大块工作。好的模型能减少分析的工作量,把握好历史非常规事件、深入全面地数据分析有利于历史数据的还原和清洗,这样能使预测模型更加稳健、预测结果更加准确。
2、捕捉未来信息:未来趋势能从历史数据中通过模型计算外推得到,这是预测得以进行的基础,但未来发展的不确定性是预测最大的敌人。对未来的不确定性因素如高管轮换、模式创新、思路调整、政策变更、系统优化、营销开展、同业关联……这都会影响未来呼入量的趋势动向,其特点在于影响因素倾向于宏观决策层面,这些因素尽管不是经常发生而且可能影响具有一定的滞后性,但其往往能改变呼入量的整体水平或决定整个客服中心的运营模式。同时在分析时很难预先用数据来推断其影响,更难以具体的数据模型来刻画,很多时候只能从业务或客户行为的角度来定性地分析。
这需要数据分析人员有着高度的商业敏感性,能敏锐地感知在历史和当前运营情况下未来可能发生的决策变化以及未来决策的影响模式、影响大小、影响时间、影响范围。从下图(如图4)可以看出,业务1相对于业务2、3来讲更显平滑,这是因为最近三年来业务1呼入量的增长主要受到是客户量和交易量的增长影响,而业务2、3在近三年的运营中受到高层政策、业务系统、运营模式的影响非常显著。

尽管在实际运营中这些宏观影响因素主要影响年度或是中长期规划性的预测,对于月度的排班预测影响并不频繁,但是很多大型客服中心是提前一个月预测并排班,一旦这些因素的影响起效而未提前捕捉到这一信息,则会使得接下来的一个月运营非常紧张。
为了尽可能避免这种信息不对称的影响,在日常运营的中除了常规数据的积累、跟踪和分析外需要另外密切关注并做足三个方面的工作:(1)企业决策规划和高层思路的细微变化;(2)营销计划和季节性运营规律;(3)预测沟通。这三个方面的工作中最直接高效的当属预测沟通,与一线资深业务人员的预测沟通往往能跳出数据找到未来不确定因素的迹象和线索。
如果说挖掘历史数据是一门专业的数据挖掘,那么捕捉未来信息属于敏感的数据感觉,要做好中长期预测和排班预测,这两个方面要相互呼应、共同作用。
3、把握运营趋势:挖掘历史数据和捕捉未来信息是系统性地做好预测工作的两个环节和手段,而准确把握运营趋势是预测的目的和要求,预测结果是否准确、合理,最终当然是由未来真实值检验,但因为要用于精确排班,往往需要有一个人工预判和调整的过程。
预判预测结果是否准确首先要判断整体水平是否合理,其次要判断每日是否合理,我们主要从两宏观和微观两个层面来判断和比较:
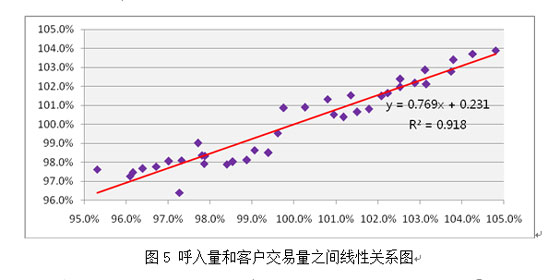
(1) 宏观评估:建立以“月”为颗粒的呼入量与历史呼入量、交易量等因素之间的传递函数自回归模型,从宏观发展的角度预测下月以及未来各月的整体呼入量水平,将宏观预测值与模型日预测总量进行比较。如果基本保持一致,则认为预测合理,无须进行大的调整;如果有较大的差异,则需再进行深入数据分析,以确定这个水平值(如图5)。
(2)微观评估:从用于每日人力上班安排的时段预测的角度钻取每15分钟的预测值,与历史同期进行比较。实际运营显示跟踪上午时段预测呼入量与近期属性(影响因素相同或相似)相同日期的时段呼入量之间的差异不会太大,因此从这一角度也可以衡量预测准确性。
把握运营趋势其实体现了组合预测的思想,日预测模型考虑的是近期趋势、特殊的周期性趋势;宏观评估则考虑了企业整体发展与呼入量之间的关系;微观评估重点考虑的是实际运营与呼入量之间的关系。不同思想考虑的因素是不一样的,反映出的信息也不同,这样思路和方法在预测过程中也会相得益彰。
三、预测模型理论
我们进行排班预测的主要模型是Intervention-ARIMA模型,其是在ARIMA模型的基础上合理地嵌入账单短信发送、还款日、节假日、系统优化、运营模式调整等具有周期规律的干预影响因素,使得模型在考虑历史数据的同时拟合出具有周期性的特殊因素的影响模式。
其中ARIMA模型又称为差分自回归移动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),是由Box和Jenkins所提出的一种经典时间序列预测方法,它将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
对于ARIMA时间序列的建模一般需要遵循以下的流程和原则:(1)模型平稳性识别:根据时间序列的散点图、自相关函数和偏自相关函数图以单位根检验其方差、趋势及其季节性变化规律;(2)模型平稳化处理:对非平稳序列进行平稳化处理,如果序列存在增长或下降的趋势则需要对数据进行差分处理;(3)模型建立:根据模型识别的平稳性原则建立合知的数学模型;(4)参数估计和检验:检验是否具有统计意义;(5)模型整体检验:诊断残差序列是否为0均值同方差的白噪声序列;(6)利用已通过检验的模型进行预测分析。
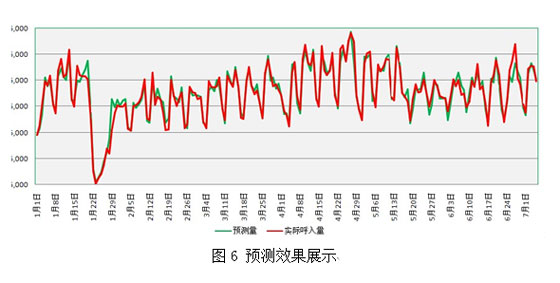
在实践过程中明确了预测工作的定义后,我们严格遵照预测流程,以综合能力较强的Intervention-ARIMA模型为基础,借助深入的数据挖掘和业务分析,使得预测效果非常显著。2011年每日预测偏差基本能控制在5%以内,60%的日子能维持在3%以内,尤其是2011年的年度预测偏差量不到5000通(如图6)。
本文刊载于《客户世界》2012年9月刊;作者万平为中国光大银行电子银行部客服中心(北京)数据分析师;李成为中国光大银行电子银行部客服中心(北京)品质管理室经理;段娜为中国光大银行电子银行部客服中心(北京)综合业务室经理。
转载请注明来源:挖掘历史数据 捕捉未来信息 把握运营趋势
客户世界
这家伙很懒,什么都没写!

噢!评论已关闭。