数据标注及模型训练在银行智能服务 领域的应用研究
随着大数据和物联网的发展,人工智能发展与应用的第三次浪潮已经来临。海量数据为人工智能发展提供基础,运算力的提升大幅推动人工智能进步,深度学习算法在图像、语音、自然语言处理等方面的突破性进展促进了人工智能的研究和应用。同时,AI算法的开源使得人工智能从专用技术成为通用技术,融入各行各业的应用中。建行智能小微正是这次人工智能发展浪潮中涌现出的典型之一,其发展的主要基础便是数据标注及模型训练。本文旨在介绍数据标注及模型训练在建行智能服务领域的应用情况,预测该技术未来发展趋势,为我行智能化水平的持续提升提供参考。
一、数据标注与模型训练的定义及市场应用
(一)定义
人工智能所依赖的数据如何加工,把海量无序的数据变成机器能够理解的数据,并在此基础上实现业务需求?这就分别需要数据标注和模型训练。数据可分为两种类型:“被标记过”的数据和“未被标记过”的数据。“标记”意同“贴标签”,例如:在“教机器人认识苹果”这项任务中,需要有大量图片,其中一大部分图片中含有苹果,在含有苹果的图片的附加字段中,标注了“苹果”的标签,机器通过归纳总结图片中苹果的特征,就能够在其他图片中认出苹果了。
在这里,在海量图片上做标记的工作即为数据标注。数据标注有很多类型,按照标注方法可以分为分类、画框、注释、标记等,按照标注对象可以分为文本、声音、图像和视频。举例中的机器人学习过程就是“训练”,所形成的认知模式,就是“模型”。因此,模型训练我们可以理解为:它是一种计算,通过对被标注后的数据进行计算来产生模型,便于以后在实际结果计算中使用。
(二)市场应用
人工智能的发展离不开数据与算法,两者缺一不可。人工智能相关行业用标注好的数据来训练算法模型,然后应用到图像识别、语音识别等不同领域。通常来说,数据标注质量越高、数量越多,模型的效果就越好,产品的效果也就越好。
1.数据标注。目前结构化数据的获取方式逐渐由原先的众包平台转向专业的数据标注公司。在人工智能时代来临前,大部分公司想要得到结构化的数据,往往会选择众包平台。因为灵活性较高的众包方式不仅能适应不稳定的数据需求,而且价格成本也较低。但随着人工智能公司迅速崛起,他们需要积累符合自身应用方向,标注得更细致、更准确的数据,且数据量庞大。大部分人工智能公司自身和众包平台都无法满足要求,专业的数据标注公司便应运而生。在人工智能行业火热、大量创业公司涌现的当下,数据标注成为人工智能发展过程中一个需求量较大的环节。
2.模型训练。目前学术界基本采用以下三大类方法实现人工智能自动问答:第一类,基于信息提取的方法,先利用问题信息结合知识库资源获取候选答案,再从候选答案中甄别得到最佳答案;第二类,基于语义解析的方法,该方法关键在于将自然语言问句解析成一种表达问句语义的逻辑形式,再基于这种结构化的表达从知识库中寻找答案;第三类,基于向量空间建模的方法,与前两种方法需要人工设计规则、提取特征不同,该方法是用向量空间描述自然语言问句以及知识库中的实体和关系,利用收集的问题、答案进行各向量表征的自动训练,通过比较问句和备选答案在向量空间中的距离实现对于输入问题的回答。目前科大讯飞、上海智臻小i机器人基本使用第二、第三类识别方式,即基于语义解析,结合向量空间建模的方法实现问题解答。无论人工智能公司使用哪种自动问答原理,都离不开模型训练的过程,模型训练是决定机器人智能性的重要因素。
二、数据标注与模型训练在建行智能服务领域的应用情况及成果
(一)应用情况
现阶段,建行智能小微及行业内的一部分智能机器人,使用的是小i机器人技术,通过对标注后的交互日志进行语义拆分与计算处理,与管理后台中已有业务知识点建立索引的方式,来处理客户需求。语义模型与索引建立的准确度,除了与系统本身的计算处理能力有关外,主要依赖于数据标注的程度以及语义模型的不断优化。
图:以客户咨询为例,智能小微业务调优流程
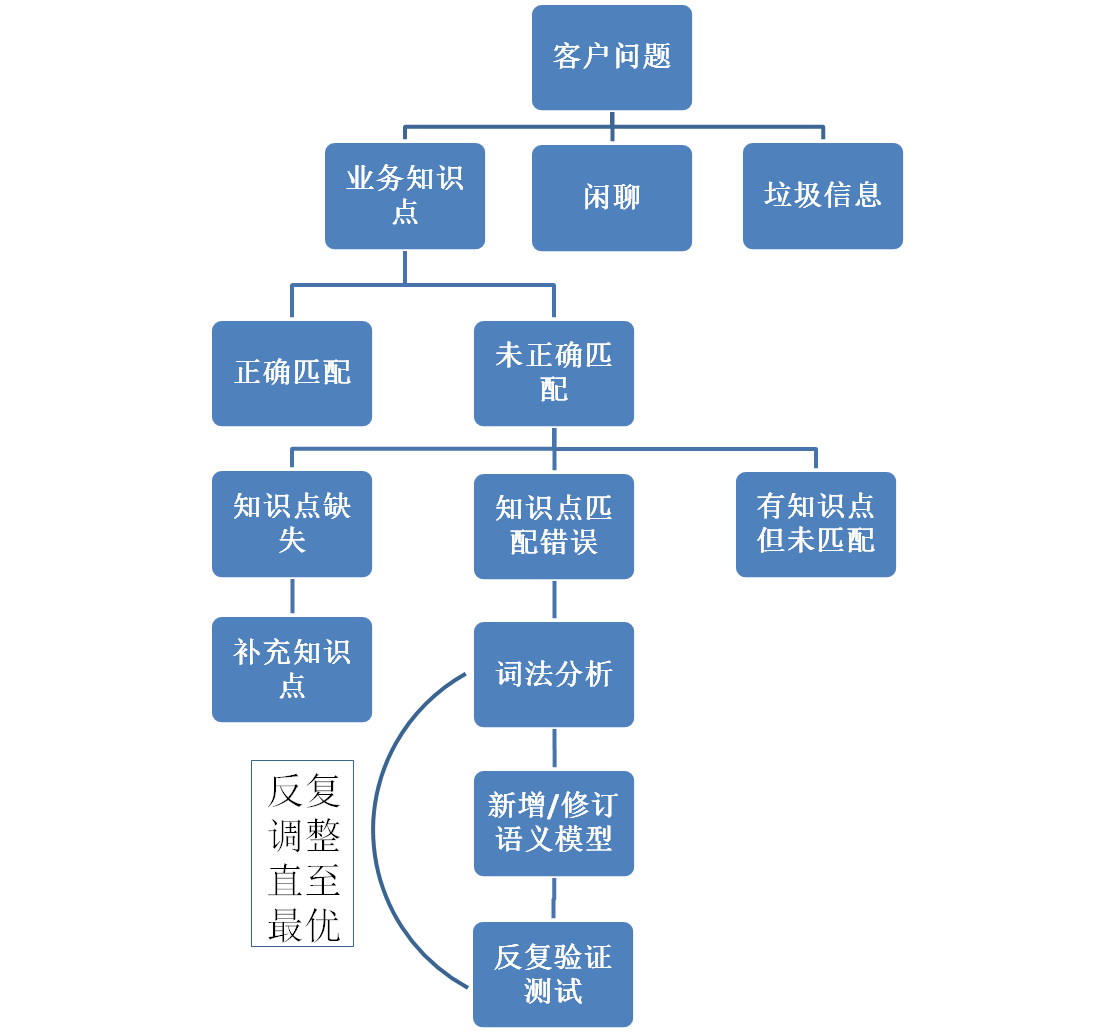
建行智能小微数据标注业务属于文本分类标注。运维人员进行文本交互日志标记,首先区分客户问题属于业务类、聊天类还是垃圾信息,再判断机器人的回答是否正确,最后针对不正确的回复分析原因。这一过程需要一个稳定且熟悉我行业务的团队来完成,人越多、分析的量越大,模型的效果就越好。
建行首先,针对客户问题进行词法分析,维护管理后台中的词类、本体类;其次,优化语义模型,纠正错误的语义模型、补充缺失的语义模型;最后,反复验证测试,完善语义模型,达到较好的匹配效果。但值得注意的是,我行智能服务模型训练的效果取决于系统本身的计算处理能力,系统如何实现自动问答,决定了模型训练的最终效果。
(二)应用成果
自2013年11月智能小微首次在微信银行亮相以来,其业务已覆盖微信、手机银行、短信、网银、网站、建行客服、微信企业号、移动门户网站、易信及深圳智慧银行十大服务渠道,涵盖建行个人金融、信用卡、电子银行、公司业务等数千个业务知识点,能够适应数万种交互场景,累计为33亿人次客户提供7*24小时标准化、专业化业务咨询服务。通过大量的数据标注和长期模型训练,目前,智能小微问题识别率[1]及应答准确率[2]均高于90%,其服务能力在同业中处于领先水平。
三、未来趋势展望
根据数据标注与模型训练的市场应用情况,结合笔者在这两项工作中的实践经验与思考,预测数据标注及模型训练两项技术未来可能会出现以下四大发展趋势:
(一)由“人工抽样标注”向“智能全量标注”转变
现阶段行业内非结构化数据分析普遍做法还停留在人为主观抽样标注,再进行数据分析,不仅数据使用率较低,且不易发现客观规律。随着大数据分析技术的进步和分析系统处理能力的提升,借助大数据分析工具,可通过机器智能实现用户交互数据由“抽样分析”向“全量分析”转变,提高数据使用率,且可以从海量数据中找到客观存在的规律。
(二)由“文本标注”向“多媒体标注”转变
目前的智能交互系统仅实现基于文本和语音的自然语言交互方式,由于银行业务场景多、规则多,文字表述冗长复杂,体验度较差。建议增加更利于客户表达和理解的展示方式,如图片、动图、视频、短片、第三方软件等,为客户带来便利、直观的交互体验。未来可通过自然语言处理、VR、AR、全息投影等技术的综合运用,以虚拟化人物形象展示,并通过人脸识别、手势识别及动态捕捉技术,进一步丰富展示效果和交互方式,为用户带来更加身临其境的展示效果和全方位的交互体验。同时,也进一步推动建行智能服务数据标注工作由“文本标注”向“多媒体标注”转变。
(三)由“简单交互”向“深度交互”转变
在当前的模型训练机制下,智能小微解决复杂问题的能力有限,无法识别一句多问、复杂语句、上下文关联语句等。未来,需要依靠“深度学习”技术的引入,让智能小微从大量的交互日志中,学习客户语言使用习惯、客户行为特征,通过上下文语句、交互场景、历史行为等,识别客户意图,进而为客户提供更智能、精准、更自然的深度交互体验。
(四)由“标准化解答”向“个性化、智能化服务”转变
目前,智能小微仅能实现简单交易及营销信息的引导和推送,基本还停留在统一的标准化问题解答。未来,可利用大数据分析工具,创新智能小微的服务模式,实现价值创造。
一方面,通过海量日志分析,抓取客户信息,捕捉客户行为习惯和交易情况等信息,精准定位客户问题,为客户提供个性化服务;另一方面,利用大数据分析工具,结合挖掘客户的潜在需求,并将客户所需与建行信用卡、速盈、快贷、善融商务等营销产品和服务结合起来,在处理客户需求的同时,定位客户可能感兴趣的产品,实现精准营销。
作者杜良艳、成璐;单位为建行合肥电子银行业务中心;
[1]问题识别率=能识别出客户问题数/客户所有问题数
[2]应答准确率=人工判断机器人回答正确数/所有有效业务问题数
转载请注明来源:数据标注及模型训练在银行智能服务 领域的应用研究
客户世界
这家伙很懒,什么都没写!

噢!评论已关闭。