浅谈客服中心话务分析与预测因子及系数获取
随着客服中心规模不断扩大,管理工作也变得日益复杂,越来越多的客服中心企业都在关注“人员效能、运营成本、合理排班”等问题,然而优化整合人员的前提是要有精准的话务预测作为指导。因此,如何准确地预测客服中心的话务量是一个重要且亟待解决的问题。
1、引言
在写这篇文章之前,也看过各位前辈、资深专家分享过的经验及文章,对于一些刚入门的小白或有些刚起步的客服中心,因人员技术限制及历史数据的积累有限等问题,有些方法暂时还不能很好地运用,而预测工作指数平滑、线性回归等方式方法是万变不离其宗,对刚起步的客服中心我们都忽略了预测之前的准备工作,而这部分工作在笔者看来是有意义的,在可控的资源条件下它会更加精确化修正话务预测结果。
在基础数据不完善和存在缺失的情况下,如何对话务变量的重要因子进行有效提取和确认是本文中探讨的重点问题。笔者将浅谈话务预测准备工作中的人工服务请求量异常数据清理工作,将话务预测公式中:某日话量=日平均话量*年度增长*因素*权重,因素提取做简单分步的提取及测算其系数,工具将采用的是Excel测算。在此需要备注说明,本文工作预测仅为人工服务请求量,暂未包含IVR语音自助及其他线上性预测工作。
2 、相关原理
2.1因子数据确定
在客服中心,话务预测首先要确认哪些对话务会产生的因子,不同行业的客服中心会产生不同的因子。举例来说,天气因素、营销推广、节假日、人文特点等都会对话务量产生较大的影响,因此不同类型的客服中心的话务预测不可按照固定模式对因子进行固化选择,需要根据自己的实际情况进行有效的数据筛选工作,确定有效影响因子后才可进行收集、整理、清洗工作。
2.2历史数据收集
任何分析及预测工作都离不开历史数据,根据历史数据我们才能直观了解话务走向发展趋势,从中发现并总结规律。目前客服中心分别以年、月、周、日及48点作为收集数据的维度,或以上述时间维度作为各类考核基准点,但从话务预测与排班工作及实际运用角度来看,应优先采用48点维度来收集数据信息,其次选择每月、日话务量。而数据周期优先选择使用近两年或相对稳定的话务数据周期,原因与之前专家、前辈所提倡不谋而合,早期历史数据没有太大意义,或会影响后期结果效果。话务数据周期可根据各自客服中心的特点进行不同周期的因子数据优化调整工作。对于此次方法介绍,我们先采用近两年话务数据,下文对话务数据、数据名词统称为话务量。
2.3数据时间维度
数据时间维度选取的数据,可以通过分析每月话务量的总数、占比、季节、营销事件等条件,将话务量进行分类划分,方便、精确分析各类数据。下面就以2018年某地话务量为例(图1),综合每月话务量的总数、占比数据分析。我们将一年的话务量大致分为第一季度(2月份),第二季度(3月~5月),第三季度(6月~8月),第四季度(9月~10月),第五季度(11月~次年1月)。在这每个季度中,我们又将每日48点话务量细化分为工作日、非工作日及法定节假日。
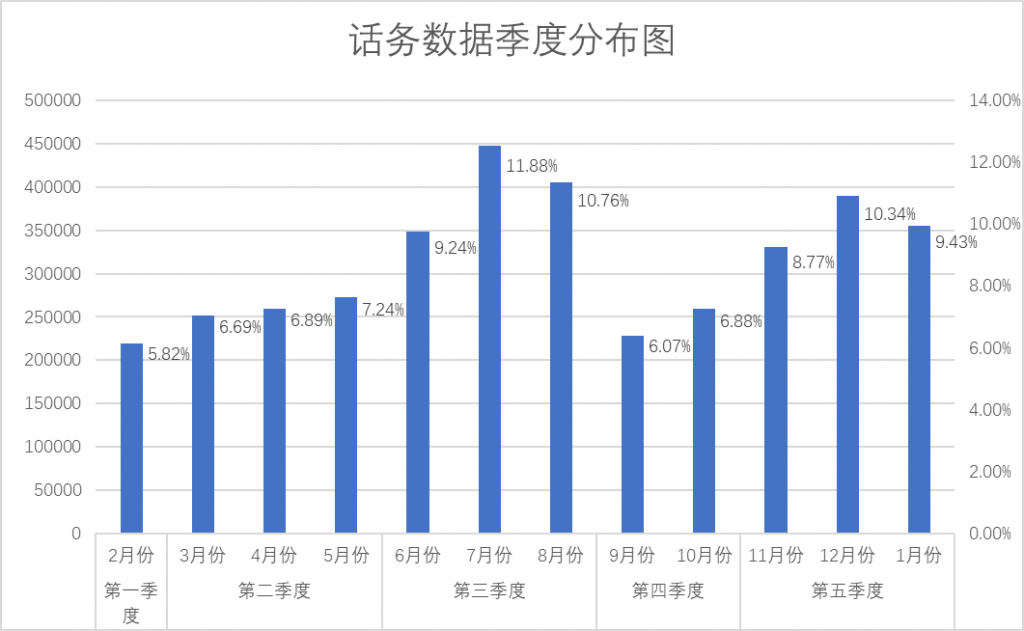
图1:话务数据季度分布图
3、 话务波动分析
3.1 理论模型
在概率论和统计学中,变异系数又称“离散系数”(Coefficient of Variation),是概率分布离散程度的一个归一化量度,其定义为标准差与平均值之比。公式为:
变异系数 C•V =( 标准偏差 SD / 平均值Mean )× 100%
一般来说,变量值平均水平高,其离散程度的测度值越大,反之越小。如果单位和(或)平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。由此可见,离散系数越大,说明波动越大,由此我们可直观地看到48点话务量波动情况。
3.2 话务波动实例分析
上文中提到,就实际工作应用的角度,48点时间维度的话务量是有价值的,它直接间接影响或指导排班,有效地提升人员能效及人员分布的作用,所以在此介绍一下48点波动点分析及方法。
行业常规中经常把异常数据利用各种清洗数据手段给其清洗掉,而不对异常数据进行分析,但通过我们对异常数据的实际研究,从中得出的话务因子及其系数,从而优化话务预测准确性。
以某地1月份话务量为例,准备2018年1月份每日48点数据(图2),根据历史话务量趋势及话务特点,暂将某地数据分为工作日及非工作日两大维度,而后将当月每日同时间点数据做变异系数计算得出离散系数。当然此类方法,亦可做本周、本月离散系数,以此看出波动幅度情况。
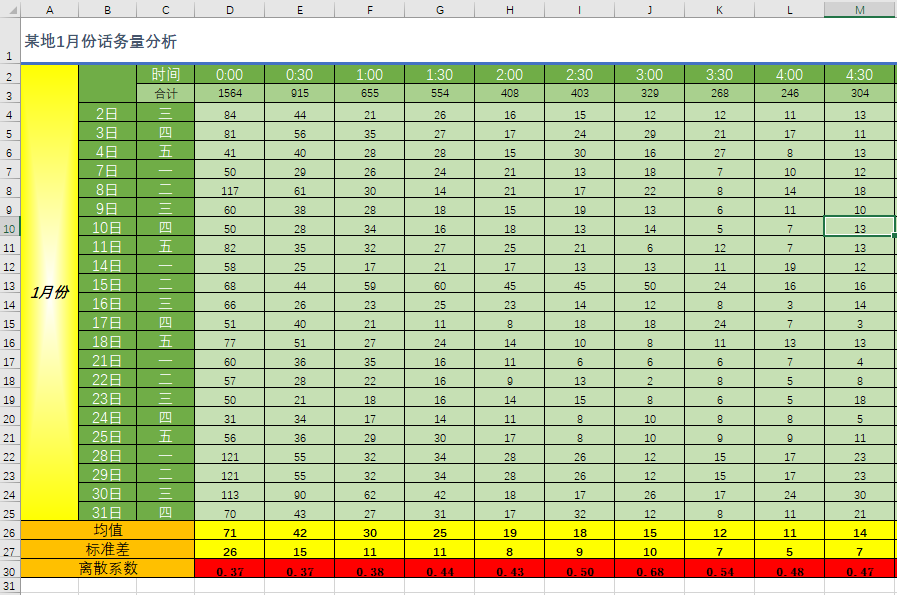
图2:某地1月份话务量每日48点数据
4 、因子系数的测算
4.1 理论模型
4.1.1人员AHT测算
人员的AHT测算按照广义来说分为两种,高能效的AHT和低能效的AHT。简单来说,高能效的AHT主要存在于对接听率要求相对较低,对人力资源成本核算要求较高的客服中心多以外包类客服中心为主,成本效益相对较高;低能效AHT存在于社会服务类客服中心,社会服务感知要求较高,利润考虑度较低。以AHT核算话务接听情况就关联客户的重复拨打情况,对于话务预测的准确度有较大的影响因素。
1)、高能效AHT,此类客服中心对于人员能效管理要求较高,在岗时间内多以满负荷工作状态为主,人员AHT基本处于一个较高水平,当日接听话务能力波动比较低,能相对准确地测算出人员的接听能力。话务因素影响较低,可对客户的呼入习惯、呼入需求进行较为准确的测算,同时根据客户的放弃率,可测算出话务量的增幅比例。
2)、低能效AHT,此类客服中心在排班过程中按照较高的接听率进行人员拟合排班,相同人员在不同时间段的AHT能效波动较大,无法有效体现人员的基础能效值,话务低谷情况下人员能效值偏低,话务高峰时段人员能效会出现提升,但话务放弃量出现大幅度上升。此类客服中心无法有效按日AHT进行核算,仅可采用AHT进行能效情况的估算。
4.1.2工单类型
工单类型及分类可间接体现每通电话客户来话的原因、需求、诉求。这其中,可通工单类型数量占比分析出电话客户来话习惯规律,及工作中问题专项提升方向等其他角度分析挖掘。对于话务预测工作而言,可根据工单类型数据占比反推出当日哪类因子影响当日话务量造成峰涌,以及证明、校验各类因素对话务量影响的维度关联。以2018年某地全年话务量为例,由下图可见(图3、图4),受高温天气因素影响,气温越高,工单量也呈上涨趋势,其中故障类工单数量较多,约占总工单量的40-50%,而其他类工单也受此因素影响呈上升的趋势。由此看出,工单量可以反推出当日话务量。
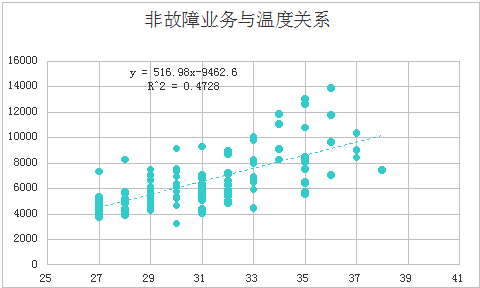
图3:非故障业务与温度关系
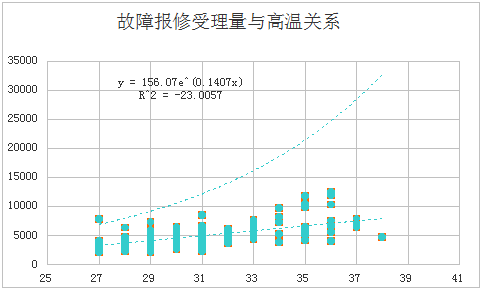
图4:故障报修受理量与高温关系
4.1.3测算重复拨打情况占比
客户重复来电拨打情况也会对话务预测的准确率造成较大的影响。重复拨打分为多类情况,人员匹配度低(高AHT客服中心)故意放弃部分话务,业务事件的影响因素、突发因素影响等内容。重复拨打需要根据不同的情况进行分类的测算,不可同一而论。
4.1.4现场人员收集
现场人员收集法,主要的涉及对象即为现场调控人员,现场的人员情况、能效情况、及话务突发情况等其他突发情况,此岗位人员从管理层角度来说是第一接触人,由此岗位人员根据现场实际情况上报、下达相关调令指挥及其他应急预案启动。考虑到现场人员在突发事件下的紧急情况,可由现场人员简单记录5分钟峰涌情况、排队情况、峰涌时段、峰涌原因情况等情况即可,而后可交由话务预测分析专员做详细分析参考。
图5为现场记录因子的简单模板,而此模板仅作为在遇到异常话务情况下填写,只需填写异常突发时段数据,如无异常突发情况无需填写。当然各客服中心情况不同,也由此可以作为借鉴进一步改良创新,或长期记录填写。
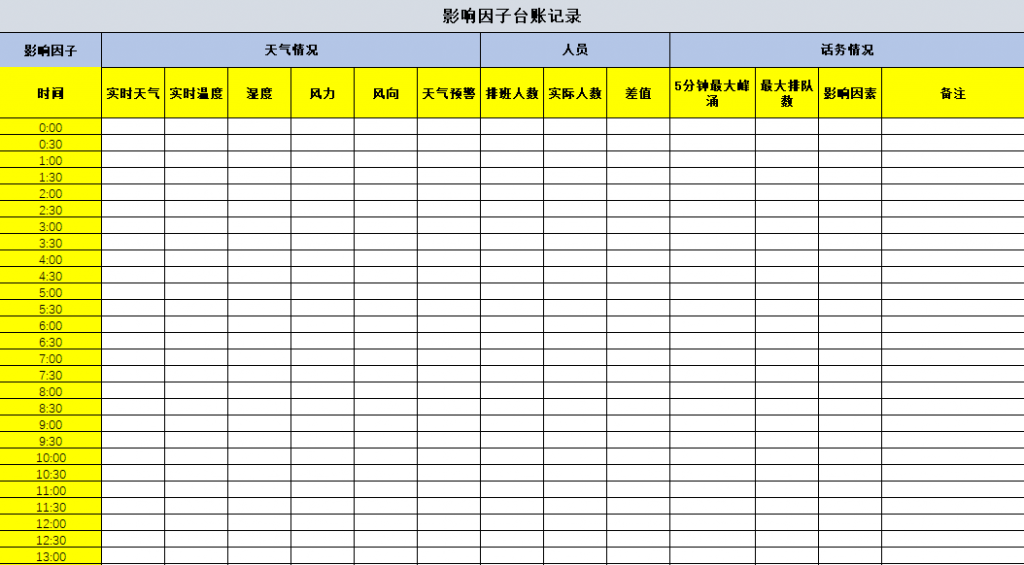
图5:现场记录因子模板
4.2 因子系数的测算及分析
通过大量准备工作,在话务数据中发现异常波动点,并通过四种维度发现异常波动点的真实原因,在话务预测工作中来说,可将此波动点的原因记录为因子,而参与预测测算工作的即为因子系数。
因子系数的获取,对于呼叫行业内,也许会有很多种的方法,大多数的呼叫中心使用的是SPSS等其他数据分析类软件分析出因子系数。在这里目前使用均值类算法去测算基准值及其系数。结合48点话务数据及波动点分析,将工作日及非工作日每48点话务量测算出一个48点均值,当期话务量以此均值为基准点,测算出差值,利用此差值得出此类系数。
本文刊载于《客户世界》2019年5月刊;作者殷春阳、韩佳伟单位为国家电网客户服务中心北方分中心;
转载请注明来源:浅谈客服中心话务分析与预测因子及系数获取
编辑
《客户世界》杂志编辑。有关投稿,呼叫中心企业培训,会议等咨询。可添加编辑潘老师微信:18710108460 或者扫描左边微信二维码进行咨询!

噢!评论已关闭。